
Table of Contents
- Purpose of the Report
- Introduction to Privacy-Enhancing Technologies (PETs)
- Types of PETs and Plain-Language Explanations: A Glossary
- Key Considerations for Decision-Making
- Combining PETs to Maximize Utility and Privacy
- Practical Considerations and Barriers to PET Adoption
- Advancing the Use of Privacy-Enhancing Technologies
- Conclusion
- Appendix 1. Key Term Definitions
- Appendix 2. Key Evaluation Questions for Privacy-Enhancing Technologies (PETs)
Combining PETs to Maximize Utility and Privacy
The combination of privacy-enhancing technologies (PETs) depends on the data flow and lifecycle—which include how data is collected, processed, shared, and analyzed. Aligning PET selection with the data cycle and intended utility helps organizations maximize both privacy and the value of their data.
Some PETs require a sequential approach because certain protections must be in place before the next stage of processing. For example, a government agency managing benefit enrollment might first apply encryption in transit to secure personal and financial information as it moves between systems and then use homomorphic encryption to analyze eligibility criteria without exposing individuals’ raw data. Similarly, k-anonymity might be applied to de-identify enrollment data before generating synthetic datasets that enable policy analysis without revealing specific applicants.
In other cases, PETs can function independently or in parallel, depending on the privacy risks and data-use requirements. For example, differential privacy can be applied directly to reports on program participation to prevent re-identification, while federated learning allows agencies to collaborate on improving benefit delivery without sharing individual records. Since these techniques address different risks, they do not need to be applied in a strict sequence.
Choosing the right PET approach requires understanding the full data lifecycle. This means assessing the sensitivity of the data, the risks at each stage, and the level of privacy protection required while ensuring the data remains useful. If data will be shared across agencies or undergo multiple transformations, a sequential approach may be necessary to maintain privacy at every step. If privacy risks are distinct and manageable separately, PETs can be applied independently.
Sequential: K-Anonymity and Synthetic Data
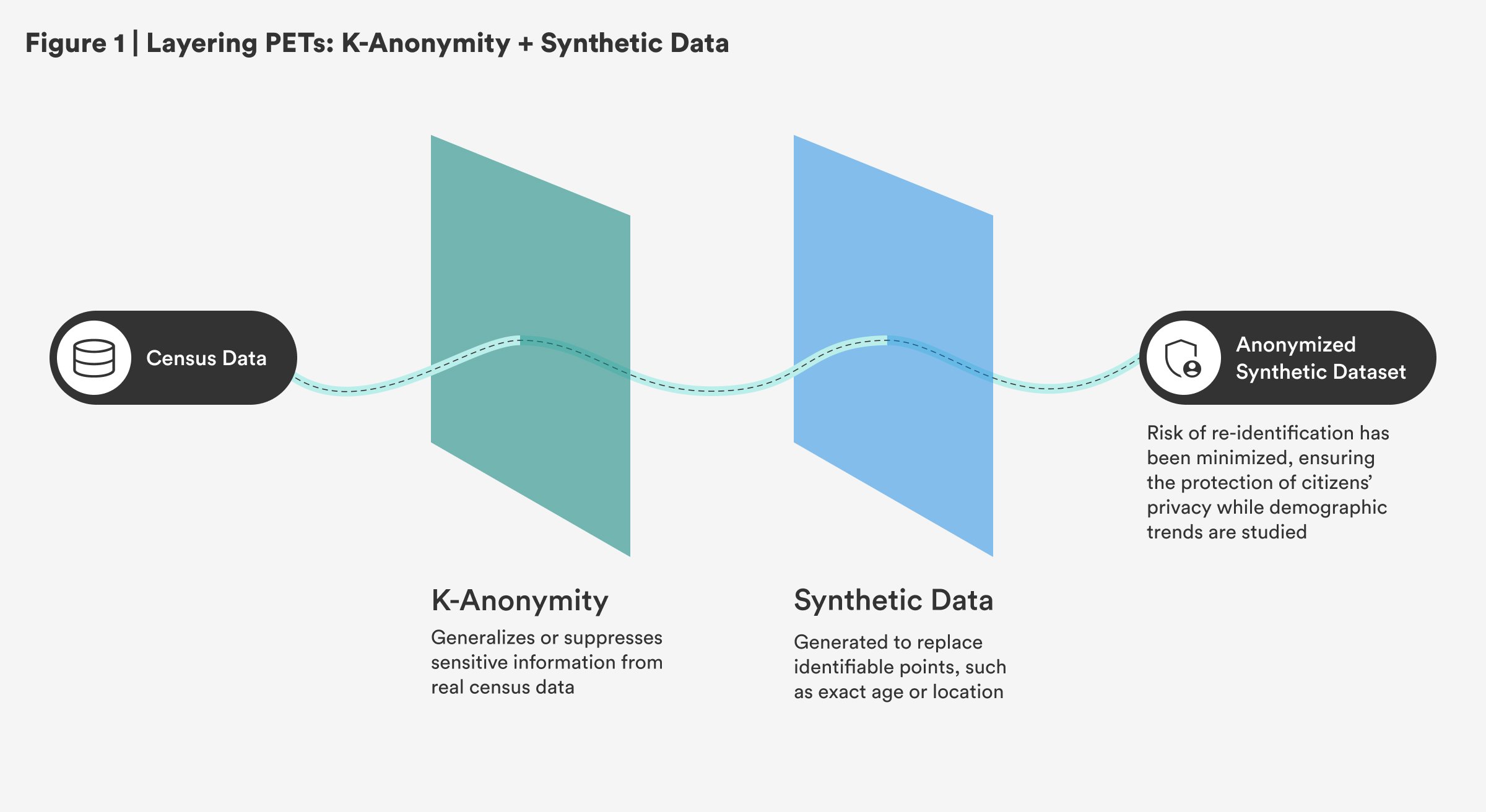
Governments could apply k-anonymity to real census data, ensuring that individuals’ identities are protected by generalizing or suppressing sensitive information. Then, they could generate synthetic datasets to replace specific, identifiable data points, such as exact age or location, enabling continued research and policy development without compromising citizens’ privacy. This approach ensures that demographic trends are studied while minimizing the risk of re-identification.
Sequential: Tokenization, Hashing, and Differential Privacy
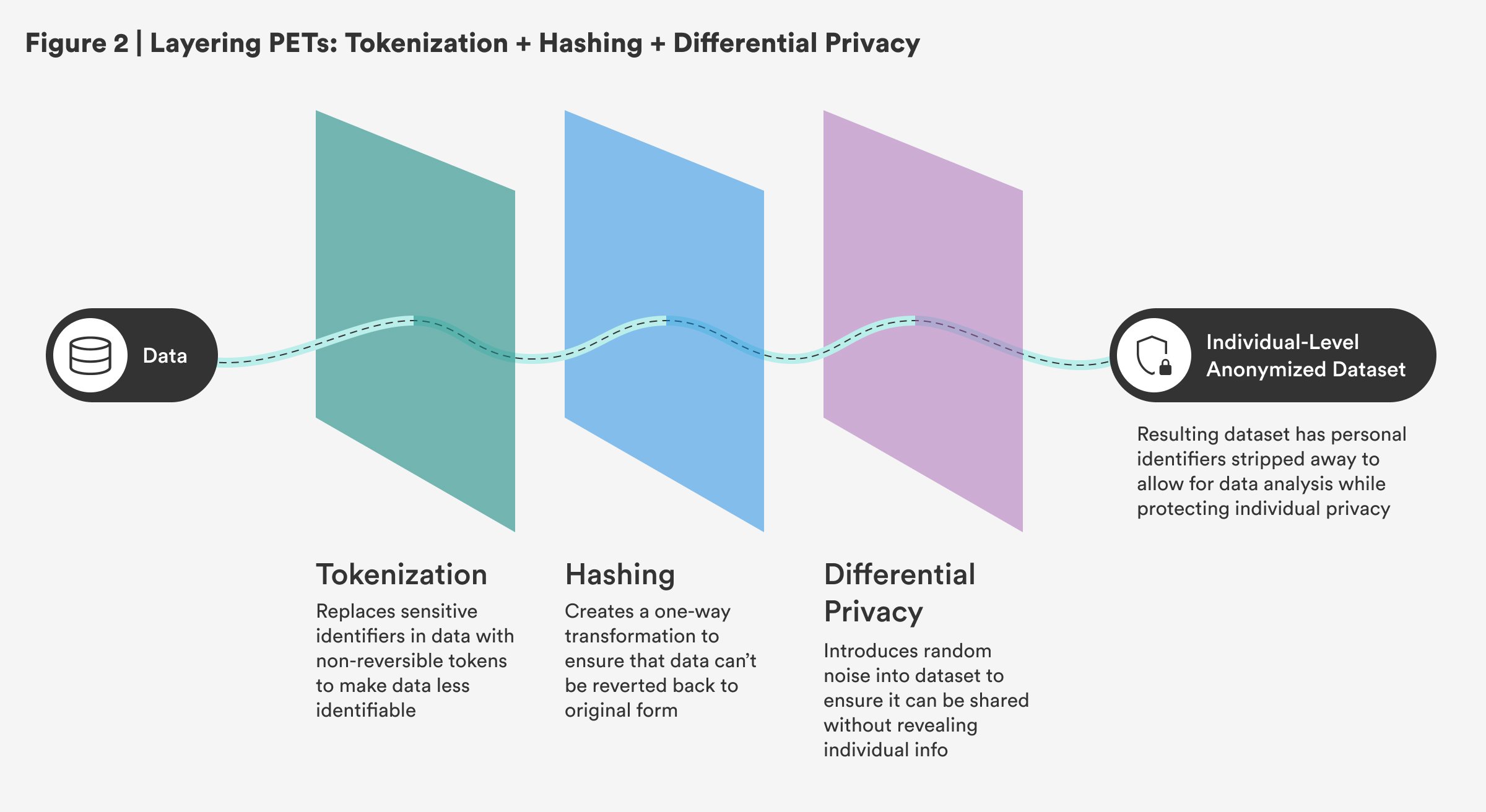
The combination of tokenization, hashing, and differential privacy in a sequential process works by progressively securing data at each step. First, tokenization replaces sensitive identifiers with non-reversible tokens, making the data less identifiable. Then, hashing further secures the tokenized data by creating a one-way transformation, ensuring that even if data is exposed, it can’t be reverted back to its original form. Finally, differential privacy ensures that the data can be shared or analyzed without revealing individual-specific information by introducing random noise into the dataset. This sequential approach is critical in creating an individual-level anonymized dataset, as seen in the census, where personal identifiers are stripped away to allow for data analysis while protecting privacy.
Non-Sequential: Tokenization and Secure Multi-Party Computation
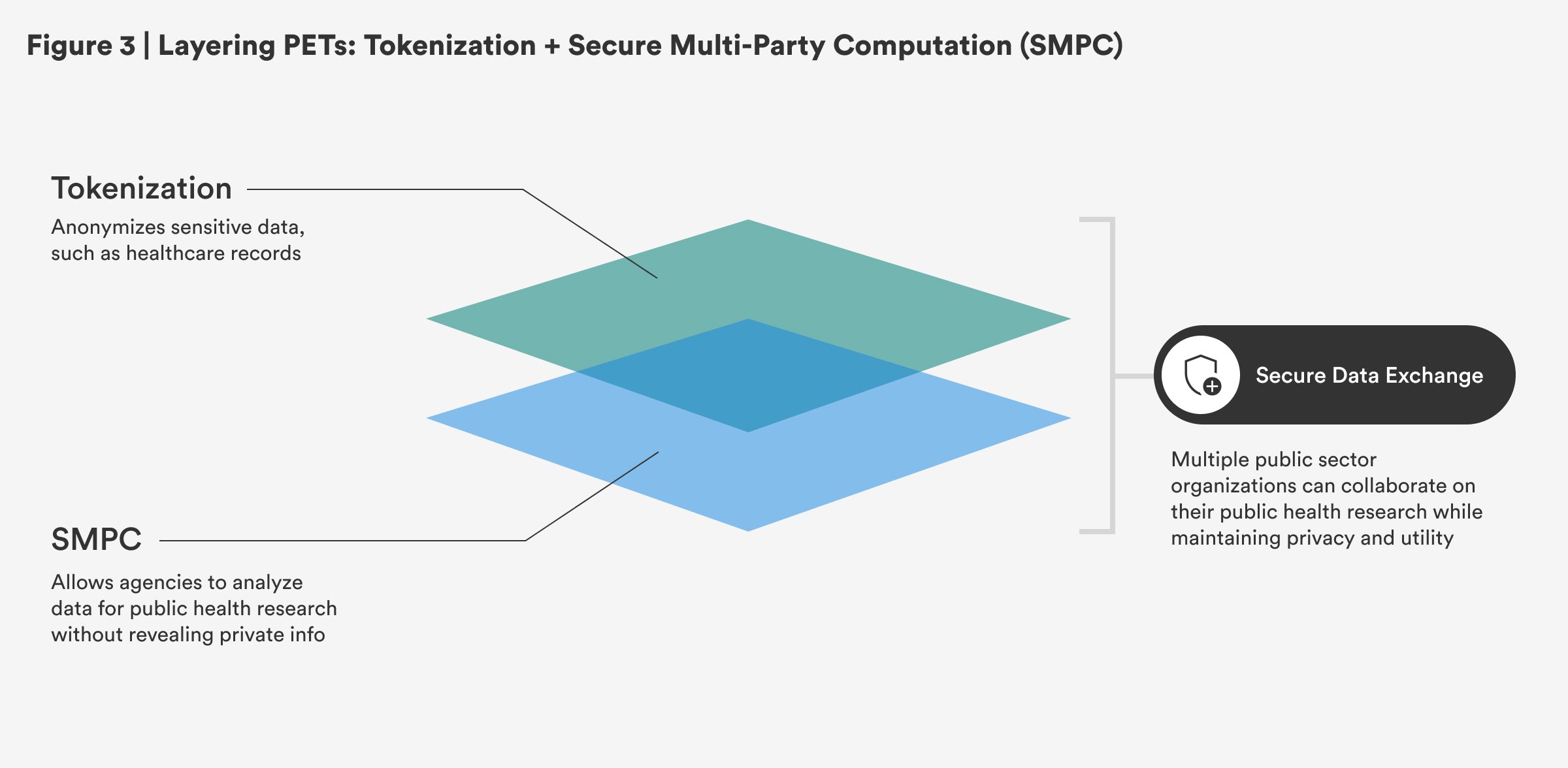
Tokenization and secure multi-party computation (SMPC) can be used by public sector organizations to enhance privacy while enabling collaboration. Tokenization anonymizes sensitive data, such as health care records, before sharing it between agencies, ensuring personal information remains protected. SMPC allows agencies to analyze the data for public health research without revealing private information. Since tokenization and SMPC operate independently, this approach is non-sequential while maintaining privacy and utility.