
Table of Contents
- Purpose of the Report
- Introduction to Privacy-Enhancing Technologies (PETs)
- Types of PETs and Plain-Language Explanations: A Glossary
- Key Considerations for Decision-Making
- Combining PETs to Maximize Utility and Privacy
- Practical Considerations and Barriers to PET Adoption
- Advancing the Use of Privacy-Enhancing Technologies
- Conclusion
- Appendix 1. Key Term Definitions
- Appendix 2. Key Evaluation Questions for Privacy-Enhancing Technologies (PETs)
Key Considerations for Decision-Making
When deciding which privacy-enhancing technology (PET) to use, there are several key factors to consider. These factors include the type of data, the sensitivity level of the data, the data-sharing needs, the required privacy guarantee level, and scalability requirements. Each of these considerations plays a critical role in determining which PET is best suited for a particular use. Table 1 breaks this down in a more visual way, making it easier to compare and understand how each factor influences the choice of the most appropriate PET for a specific situation. For a more detailed explanation of the questions used to evaluate each PET, please refer to Appendix 2.
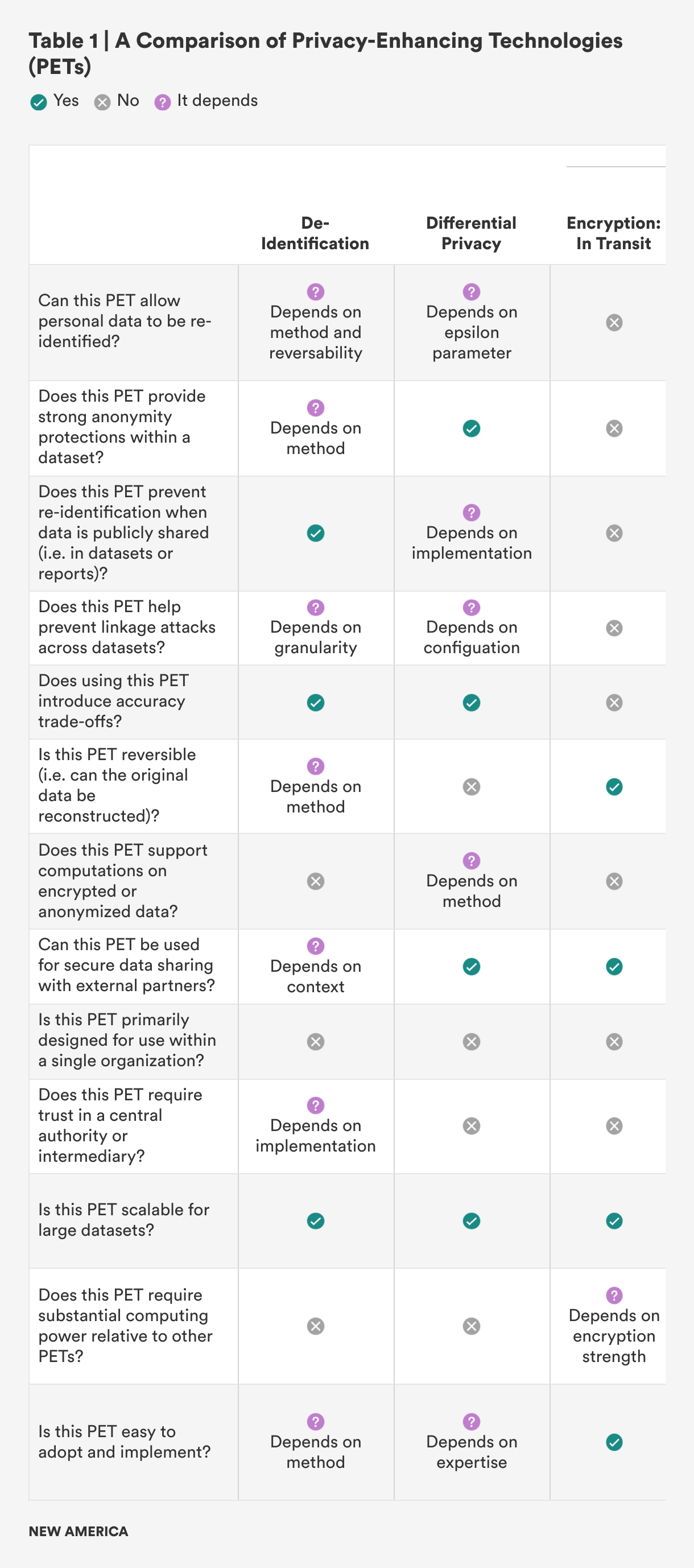
The type of data is one of the most important considerations when selecting a PET. For example, if the data contains personally identifiable information (PII), such as names, Social Security numbers, or addresses, the technology chosen must be capable of protecting individuals’ identities. PETs like encryption, tokenization, and differential privacy are specifically designed for handling sensitive PII and ensuring that individual records are protected.1 On the other hand, if the data is aggregated or anonymized—such as trends or summaries without any direct identifiers—the requirements for privacy protection may be less stringent. In these cases, techniques like generalization or federated analytics may be sufficient, as they preserve privacy while allowing for broader data analysis without exposing specific individual information.
The sensitivity level of the data also determines the privacy measures needed. Highly sensitive data, such as medical records or financial information, demands more robust security measures to prevent breaches or misuse. For such sensitive datasets, PETs like homomorphic encryption or secure multi-party computation (SMPC) can provide strong privacy guarantees by ensuring that the data remains encrypted even during processing and analysis, thus minimizing the risk of exposure.2 In contrast, data with medium or low sensitivity, such as business analytics or public records, may not require as strict of protections. For these types of data, techniques like de-identification or k-anonymity may offer a sufficient balance between privacy and usability, as they can anonymize or group data without significantly diminishing its usefulness for analysis.3
Another critical factor to consider is data-sharing needs. The level of privacy protection required can vary greatly depending on whether the data will be shared within a trusted environment or with external partners. For example, if data is being shared within a government agency or between departments with strong internal security controls, the privacy requirements may be less strict, and basic encryption techniques or tokenization might be adequate.4 However, if data is being shared with external entities, such as third-party vendors, contractors, or researchers, stronger privacy protections are necessary to ensure that sensitive information remains secure and that unauthorized access is prevented. In such cases, PETs like federated learning, private set intersection, or differential privacy allow for secure data sharing and analysis while ensuring that individual-level data is not exposed to external parties.5
The required privacy-guarantee level plays a significant role in selecting a PET. Some applications prioritize maximum privacy, even if this means sacrificing data precision. For example, when dealing with extremely sensitive data, high-privacy guarantees may be necessary, even if this reduces the precision of the data. Techniques like differential privacy introduce random noise to datasets, ensuring that the privacy of individuals is protected while allowing for aggregate analysis.6 On the other hand, some use cases require a more balanced approach, where a moderate level of privacy is acceptable but maintaining data precision is still important. In these scenarios, PETs like k-anonymity or tokenization may offer a good compromise, as they protect personal information while still allowing for detailed, actionable insights from the data.7
Finally, scalability requirements are a crucial consideration when selecting a PET. As datasets grow in size, the scalability of the privacy-enhancing technology becomes more important. For smaller datasets, more resource-intensive PETs like homomorphic encryption or SMPC might be feasible because the computational overhead is manageable.8 However, for large datasets, it’s essential to choose a PET that can scale without compromising performance. Techniques such as federated learning or federated analytics are particularly useful in large-scale environments because they allow data to be processed across multiple devices or servers, ensuring that privacy is maintained without the need to centralize sensitive information.9 Additionally, distributed encryption and generalization techniques can scale well to handle large volumes of data while still preserving privacy.10
In summary, selecting the appropriate PET depends on the specific data characteristics and the intended use case. By carefully evaluating the type of data, its sensitivity level, sharing needs, privacy guarantees, and scalability requirements, organizations can choose the right PET to meet their privacy and security goals while still enabling effective data analysis.
Citations
- Centre for Data Ethics and Innovation, Privacy-Enhancing Technologies Adoption Guide, source.
- United Nations, The PET Guide, source.
- United Nations, The PET Guide, source.
- U.K. Information Commissioner’s Office, Chapter 5, source.
- U.K. Information Commissioner’s Office, Chapter 5, source.
- Rachel Cummings et al., “Advancing Differential Privacy: Where We Are Now and Future Directions for Real-World Deployment,” Harvard Data Science Review 6, no.1 (2024), source.
- U.K. Information Commissioner’s Office, Chapter 5, source.
- J.M. Auñón et al., “Evaluation and Utilisation of Privacy-Enhancing Technologies—A Data Spaces Perspective,” Data in Brief 55 (August 2024), source.
- Samaneh Mohammadi et al., “Balancing Privacy and Performance in Federated Learning: A Systematic Literature Review on Methods and Metrics,” Journal of Parallel and Distributed Computing 192 (October 2024), source.
- P. Ram Mohan Rao, S. Murali Krishna, and A. P. Siva Kumar, “Privacy Preservation Techniques in Big Data Analytics: A Survey,” Journal of Big Data 5 (2018), source.